Static analysis is a popular approach to malware detection. Static analysis provides thorough analysis of source code of portable executable (PE) files without executing them, allowing early stage detection of malicious programs. Detecting the malicious file before it executes is highly effective to minimize the risk of malware contaminating the system. Static analysis can be used to extract many features from the parsed PE file such as: section names, order of the sections, entropy of sections, imported DLL’s, suspicious strings, usage of specific functions, code sections snippets, etc. PE feature extraction is lightweight compared to dynamic approaches like sandboxing and is not limited to a set of predefined signatures as in traditional anti-viruses.
Since there are many PE features whose importance and dependence are not clear, traditional methods, such as scoring, are useless to discern between benign and malicious software. Therefore, machine learning based malware detection methods should be applied. Machine learning methods have already been proven useful tools for solving similar problems. They leverage features extracted from malicious PE files, to learn models that distinguish between benign and malicious software [1]. In addition, machine learning can automatically extract the importance of the features and dependencies between them.
The Cyberbit Malware Research team conducted machine learning cyber security research in which we applied supervised machine learning techniques to create a classifier that uses static analysis to detect malware in the form of Windows PE files.
Dataset
A. Data Set Collection
We collected 51,000 unique benign Windows PE files from endpoints and extracted features from them. We used our harvesting system to collect 17,000 unique malicious Windows PE files from various sources, these PE were verified as malicious using Virus Total [2]. We stored all the malware sample files in a clean environment and extracted from the malicious PE files the same set of features extracted from the benign PE files.
B. Features Extraction
Windows PE files can be either executable files or files that contain binary code used by other executable files. In this study, we parse the PE file according to the PE structure and extracts features from the parsed PE file. The extracted features can divide into four categories:
- PE Header Information
PE files have a header that contains information about the PE file and how the OS should execute it. The header can be used to extract a known set of features regardless of the PE size. All PEs have the same header and structure which enables us to collect the same set of features for a wide variety of PEs. - Section Names and Characteristics
Each PE usually has one or more sections that contain the actual body of the PE. Sections can include binary code, strings, configuration, pictures and so on. Standard PEs usually have similar section structures in terms of names, order, and characteristics. Malicious PEs sometimes have different structures due to evasion techniques that are used to avoid detection and classification.
The difference in section structure and names is due to several factors including the compiler used to generate the PE. Malicious PE files are often generated by custom compilers which enables them to perform operations on the PE files that are not supported by regular compilers. Examples of such operations are: packing, encryption, manipulation of strings, obfuscation, anti-debugging features, stripping of identifying information, etc.
Some section names that are associated with known builders, compilers and packing infrastructure include:
| Section Names | Builders/Compilers/ Packing Infrastructure |
| Mpres | Mpres Packer |
| Upx | UPX |
| Tsuarch | TSULoader |
| Petite | Petit packer |
| Rmnet | Ramnit Packer |
| Nsp | NsPack packer |
| Aspack | Aspack packer |
| Themeda | Themida |
| Adata | Armadillo packer |
| Vmp | VMProtect |
| Mew | MEW Packer |
| Neolit | ImpRec-created section |
| Newsec | LordPE Builder |
| Taz | PESPIN |
| gfids | Visual Studio (14.0) |
| stab | Haskell compiler (GHC) |
- Section Entropy
The PE sections contain data which usually has a known entropy. Higher entropy can indicate packed data. Malicious files are commonly packed to avoid static analysis since the actual code is usually stored encrypted in one of the sections and will only be extracted at runtime. Many malware use a known packing utility such as: Themida, VMProtect, UPX, MPress, etc. There are also numerous custom packers that high-end malicious actors use to implement their own custom encryption algorithms.
Usually, an entropy level of above 6.7 is considered a good indication that a section is packed. However, there are some custom packers that use padding as part of the encryption process to generate less entropy in the compressed section. Luckily these packers are not very prevalent. - PE Imports
A PE can import code from other PEs. To do so, it specifies the PE file name and the functions to import. It is important to analyze the imports to get a coherent image of what the PE is doing. Some of the imported functions are indicative of potential malicious operations such as crypto APIs used for unpacking/encryption or APIs used for anti-debugging.Some example of potential malicious imports:
| Import Names | Potential Malicious Usage |
| KERNEL32.DLL!MapViewOfFile | Code Injection |
| KERNEL32.DLL!IsDebuggerPresent | Anti-Debugging |
| KERNEL32.DLL!GetThreadContext | Code Injection |
| KERNEL32.DLL!ReadProcessMemory | Code Injection |
| KERNEL32.DLL!ResumeThread | Code Injection |
| KERNEL32.DLL!ResumeThread | Code Injection |
| KERNEL32.DLL!WriteProcessMemory | Code Injection |
| KERNEL32.DLL!SetFileTime | Stealth |
| USER32.DLL!SetWindowsHookExW | API Hooking |
| KERNEL32.DLL!MapViewOfFile | Code Injection |
| ADVAPI32.DLL!CryptGenRandom | Encryption |
| ADVAPI32.DLL!CryptAcquireContextW | Encryption |
| KERNEL32.DLL!CreateToolhelp32Snapshot | Process Enumeration |
| ADVAPI32.DLL!OpenThreadToken | Token Manipulation |
| ADVAPI32.DLL!DuplicateTokenEx | Token Manipulation |
| CRYPT32.DLL!CertDuplicateCertificateContext | Encryption |
All these features enable us to learn about the new PE before it is executed or loaded, and therefore before it affects the system.
C. Feature Selection
Feature selection is a preprocessing technique used in machine learning to obtain an optimal subset of relevant and non-redundant features to increase learning accuracy [4].
Feature selection is necessary because the high dimensionality and vast amount of data pose a challenge to the learning process. In the presence of many irrelevant features, learning models tend to become computationally complex, over fit, become less comprehensible and decrease learning accuracy. Feature selection is one effective way to identify relevant features for dimensionality reduction. However, the advantages of feature selection come with the extra effort of trying to get an optimal subset that will be a true representation of the original dataset [3].
In our study, we extracted 191 features from each PE file. In order to reduce the dimensionality of our dataset and improve the performance of the machine learning algorithm, we used Fast Correlation-based Feature Selection (FCBF) method [5]. FCBF is a feature selection method that starts with a full set of features and uses symmetrical uncertainty to analyze the correlation between features and remove redundant features. FCBF consists of two parts:
- Select subset of
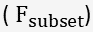 features that are relevant to the target class.
features that are relevant to the target class. - Remove redundant features and save only predominant ones in
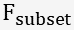 .
.
The FCBF method stops when there are no redundant features left to eliminate. The FCBF runs, in general, significantly faster than other subset selection methods [6], and is scalable and independent of a learning algorithm. As a result, feature selection needs to be performed only once [7]. After we applied the FCBF method, each PE file is represented by 55 relevant, non-redundant features.
Performance Evaluation
A. Methodology
The methodology of machine learning classification is divided into three stage cycles as depicted in Figure 2 (Learning, Features Extraction and Detection). At the end of each cycle, the results that are verified as malicious by human analysts are used as feedback to further improve the classifier for the subsequent cycle.
The first stage is the learning process. During this step, the machine learning algorithm (Random Forest) is trained using the training executable features. The training data consists of features extracted from benign and malicious executables files. The algorithm generates a classifier based on the assigned training data. In each cycle, we adjusted the learning process. We assumed that when the learning process is performed for the first time, there are no malicious files in the organization.
Next, the features extraction process is conducted. In this stage, we extract features from unknown PE files. Finally, during the detection process, the machine learning classifier classifies the testing executable files. If an executable file is classified as malicious, our system generates an alert and sends it to the analyst. We assumed that after the system generates an alert about the existence of a malicious PE file the human analyst investigates and confirms it is indeed malicious and deletes the file from the endpoints. The features of the detected malicious PE file are marked as malicious and added to the executables features dataset for the subsequent cycle.
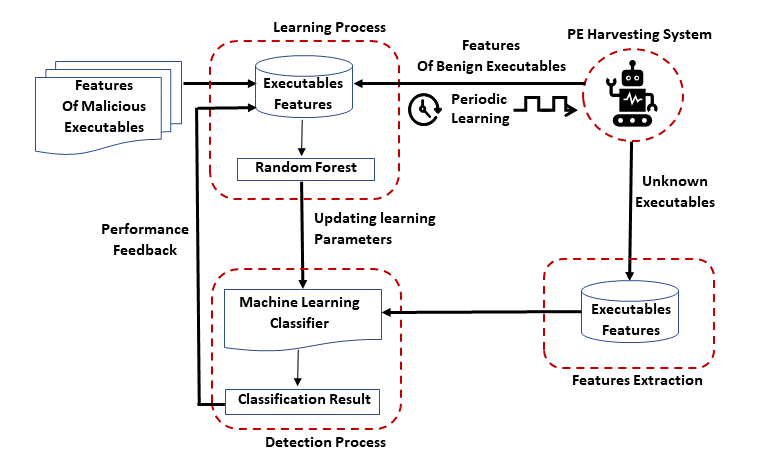
Fig. 2: Algorithm based classification methodology
B. Algorithm Explanation
In our study, we used the Random forest machine learning algorithm for several reasons. Random forest allows us to extract the importance of features and gain some insight into the detection process. Random forest has methods to handle unbalanced datasets. Since the number of benign PE files is not equal to the number of malicious PE files, we can use these methods to overcome the imbalance in our data set. In addition, random forest is an ensemble learning algorithm and therefore can prevent overfitting.
In this section, we briefly described the random forest algorithm that was applied. Random forest is an ensemble learning algorithm, that consists of multiple decision trees. The trees are constructed as follows:
- Each tree grows by using subsets of samples that are selected randomly from the original training data.
- At each node, a decision is made to achieve the best split among all the possible m variables so that the child nodes are the purest. To measure the purity of nodes the impurity criterion should be used.
- Each tree stops growing if the node becomes pure or there are minimum samples required to be at a leaf node.
The prediction of new data is performed by aggregating the prediction of the random forest trees (i.e., majority votes).
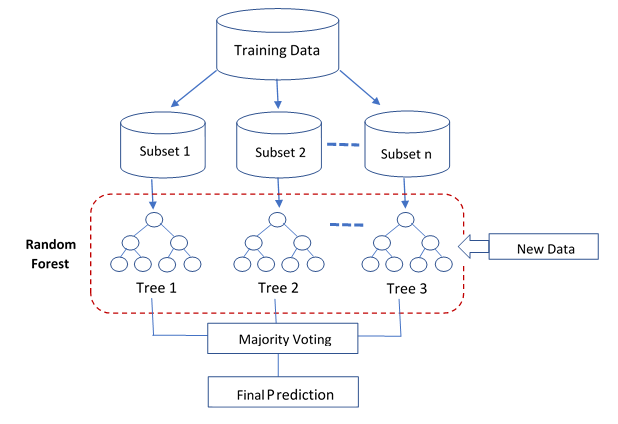
Fig. 3: Random Forest model
C. Algorithm Setup
As mentioned, in this study we incorporated feedback from human analysts to verify files identified by the classifier were indeed malicious to adjust the learning process. In each cycle, we train the random forest on features extracted from one time-period and malicious PE files. Then the algorithm generation classifier is applied during the following period to classify the testing PE files. The training data set include features extracted from ~12,000 different benign PE files and from 12,750 malicious PE files. The testing PE files include ~5000 benign PE files and 4,250 malicious PE files.
We applied the random forest algorithm by manipulating the following parameters:
- Number of trees in the random forest: 2,000.
- Impurity criterion: information gain
- Minimum samples required to be at a leaf node: 5
- Minimum number of samples required to split an internal node: 5
- Number of train periods:3
- Number of test periods:3
- Duration of each period: week.
These parameters are set using a cross-validation technique.
We examined the following measures:
- False Positive (FP): number of benign PE files that classified as a malicious.
- True Positive (TP): number of malicious PE files that classified as a malicious.
- True Negative(TN): number of benign PE files that classified as a benign.
- False Negative(FN): number of malicious PE files that classified as a benign.
- True Positive Rate(TPR): ratio of malicious PE files that classified as a malicious to all the malicious files.
- False Positive Rate(FPR): ratio of benign PE files that classified as a malicious to all the benign files.
- Accuracy: ratio of correctly classified files to all files.
- Percentage of voter’s trees: the minimum fraction of trees required to votes that the PE file is malicious.
Algorithm Performance Results
In this section, we present the results of the random forest performance. To select the best random forest model, namely the model that produced a high TP and low FP, we analyzed what is the optimal percentage of voter trees. To select the threshold for the percentage of voter trees, we use Receiver Operating Characteristic (ROC) analysis. Figure 4 presents the ROC curve. Namely, the TPR as a function of the FPR based on a single time period. Each point in the curve represents the percentage of voter trees.
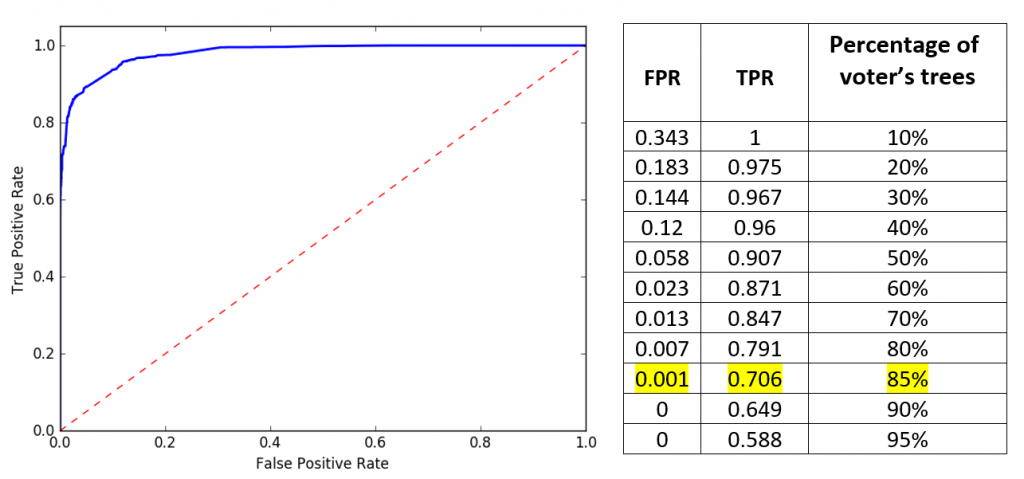
Fig. 4: ROC curve
For our system, the “ideal” point on the ROC curve is the point where there is no more than 5 FP per week: 0.001 FPR (since we have 5000 benign files). From these results, we can conclude that for our purpose the ideal percentage of voter trees is 85%. If at least 85% of trees will vote the TPR will be 0.706 and the FPR will be 0.001.
Using this threshold, we test our model on the two remaining periods. Table 1 presents the model performance averaged over the two time periods. According to the results shown in Table 1, there is an average of 5 FP per week.
| TP | TN | FP | FN | Accuracy |
| 3000 | 4995 | 5 | 1250 | 86.4% |
Table 1: Model Performance
To understand which features had the most impact on model accuracy, we extract the importance of the top 20 features from the random forest model, as shown in Figure 5.
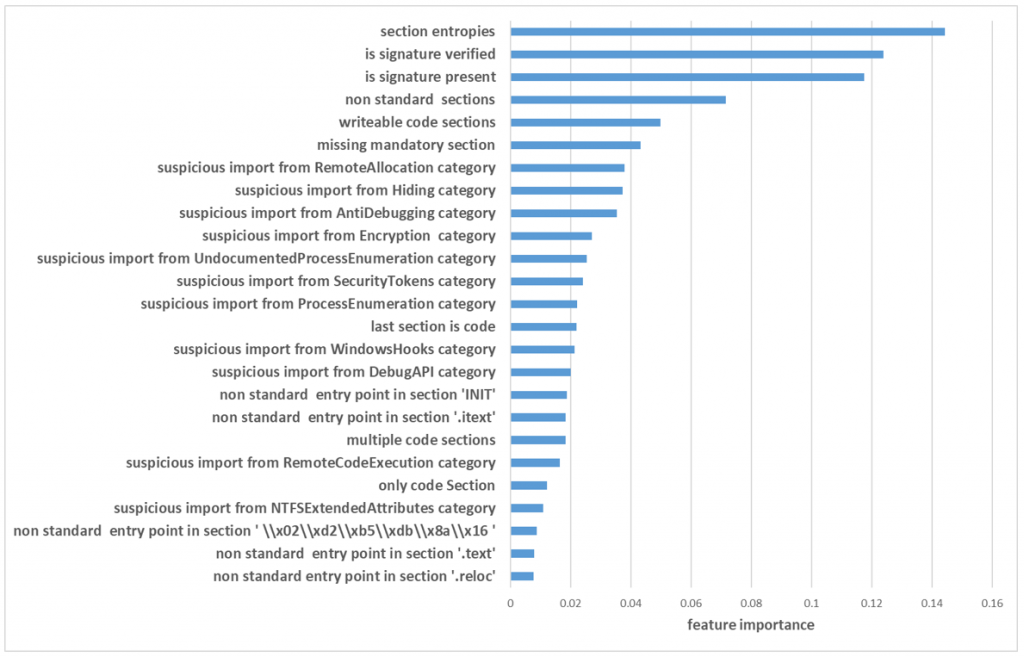
Fig. 5: Importance of The Top 25 Features
From these results, we can conclude that the most useful feature for distinguishing between benign PE files and malicious PE files is the maximum entropy of all the PE section entropies. This observation fits with our assumptions that high entropy is not common with benign PE files. In addition, it seems that there is great importance to the signature status of the file. Namely, if the PE file is not signed or it is signed with an unverified signature there is a very high probability that it is a malicious PE file.
The next most important features are related to section names and permissions. Malware often uses packing techniques to avoid being detected by antivirus signatures. This results in nonstandard sections names and write permissions.
We also notice that the categories of the suspicious import had an impact on the model accuracy. In these features, we grouped different suspicious API functions by categories such as evasion, encryption, remote allocation etc. In each group, there can be several functions from different DLLs. This allowed us to learn the malicious activity without overfitting to specific functions.
Cyber Security Machine Learning – Future Research
Our work shows that entropy, signature status, and DLL import categories have high importance. Hence, in the future, we would like to add more features from those fields. In this model, we used only the max entropy of all sections. We can add features that consider entropies of all sections in the PE. In addition, more information about the signature of the PE file should be considered, for example; the issuer of the signature, the subject of the signature, validity period, etc.
We can also extend the features of DLL imports. In addition to the suspicious import categories, we can add features that relate to number of import DLLs and number of functions in each import DLL. Moreover, we would like to check the impact of adding static properties of the import DLLs to the file from which they are imported. For example, we can add the feature of the signature status of the imported DLLs namely, the ![]() .
.
The current model uses only the suspicious PE properties as features. We can add standard static properties of the file that are currently ignored such as file size, file language, compilation time, compiler type, etc.
About the authors:
Yasmin Bokobza is a Data Scientist & Machine Learning Researcher at Cyberbit. She earned a BSc and MSc in Information System Engineering from Ben Gurion University.
Yosef Arbiv is R&D Team Leader and Windows Internals Expert at Cyberbit. He began his career in software development in the Israel Defense Forces, where he advanced to R&D leadership roles. Arbiv earned a MSc in Computer Science from Bar Ilan University.
Watch FREE webcast to learn How to Prevent the Next Financial Cyberattack with Next-Gen Technology
References
- Kolosnjaji, Bojan, et al. “Adversarial Malware Binaries: Evading Deep Learning for Malware Detection in Executables.” arXiv preprint arXiv:1803.04173 (2018).
- “VirusTotal”, https://www.virustotal.com/#/home/upload
- Mwadulo, Mary Walowe. “A review on feature selection methods for classification tasks.” International Journal of Computer Applications Technology and Research 5.6 (2016): 395-402.
- Girish Chandrashekar, Ferat Sahin, (2014). “A survey on feature selection methods”. Computers and Electrical Engineering.
- Yu, Lei, and Huan Liu. “Feature selection for high-dimensional data: A fast correlation-based filter solution.” Proceedings of the 20th international conference on machine learning (ICML-03). 2003.
- Baris Senliol, Gokhan Gulgezen, Lei Yu, Zehra Cataltepe, (2008).” Fast Correlation-Based Filter (FCBF) with a Different Search Strategy”. Computer and Information Science, 23rd international symposium.
- Yvan Saeys, Inak Inza, Pedro Larranaga, (2007). “A review of Feature Selection techniques in bioinformatics”. Bioinformatics, Oxford University Press.